
Handleiding – Health Noord Anonimisatie-tool voor Vrije Tekst
Inleiding
Deze anonimisatietool helpt VVT‑organisaties en onderzoekers om vrije‑tekstgegevens uit ECD’s veilig te anonimiseren. De tool detecteert automatisch persoonsgegevens en vervangt deze door neutrale labels zodat de informatie bruikbaar blijft voor onderzoek zonder schending van de AVG. De Health Noord Anonimisatie-tool is gebaseerd op DEDUCE [1],[2].
[1] Menger, V.J., Scheepers, F., van Wijk, L.M., Spruit, M. (2017). DEDUCE: A pattern matching method for automatic de-identification of Dutch medical text, Telematics and Informatics, 2017, ISSN 0736-5853
[2] https://github.com/vmenger/deduce
Onderstaande handleiding begeleidt je stap voor stap door het proces, mét voorbeeldschermen.
1. Voorbereiding
Download de tool of bouw de tool zelf vanuit github: https://github.com/Jesse-Snels/Health-Noord-Anonimisatie
(deze github link wordt nog vervangen door de link naar de beheerde github repository van Hanze)
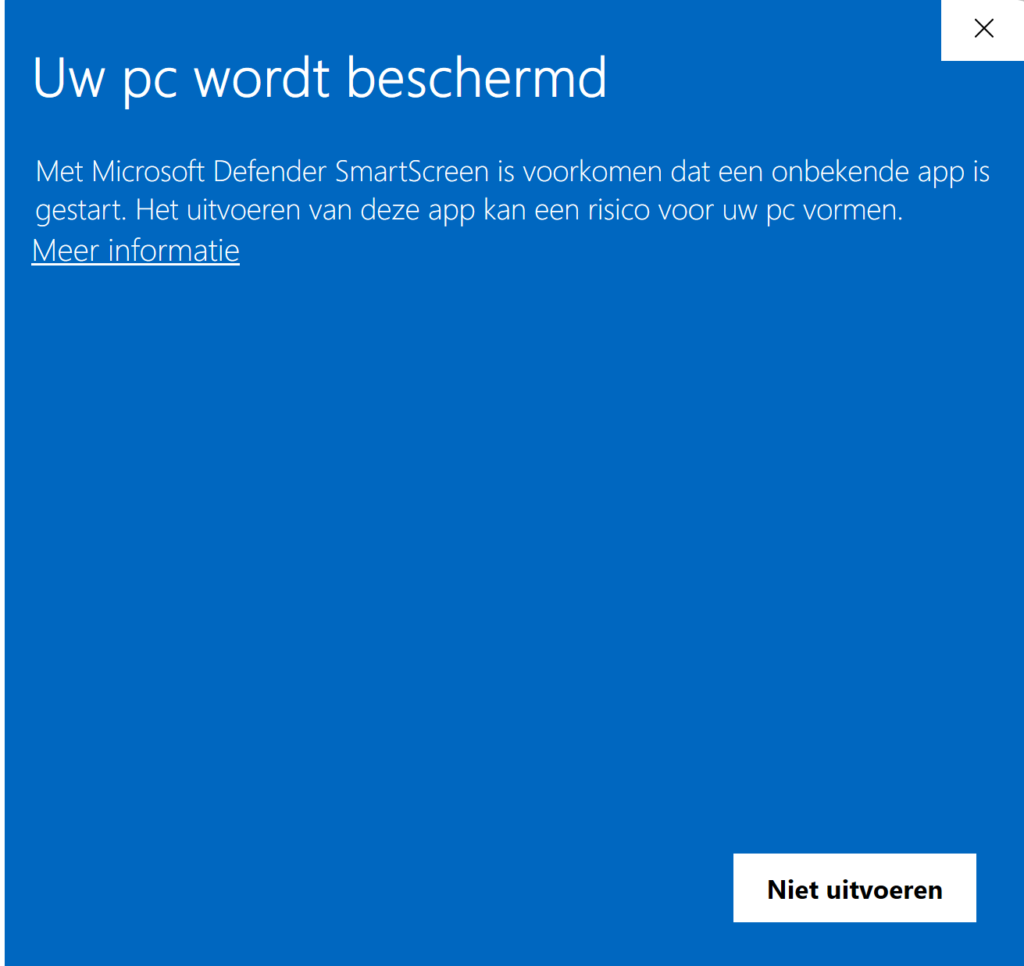
Waarschuwingen:
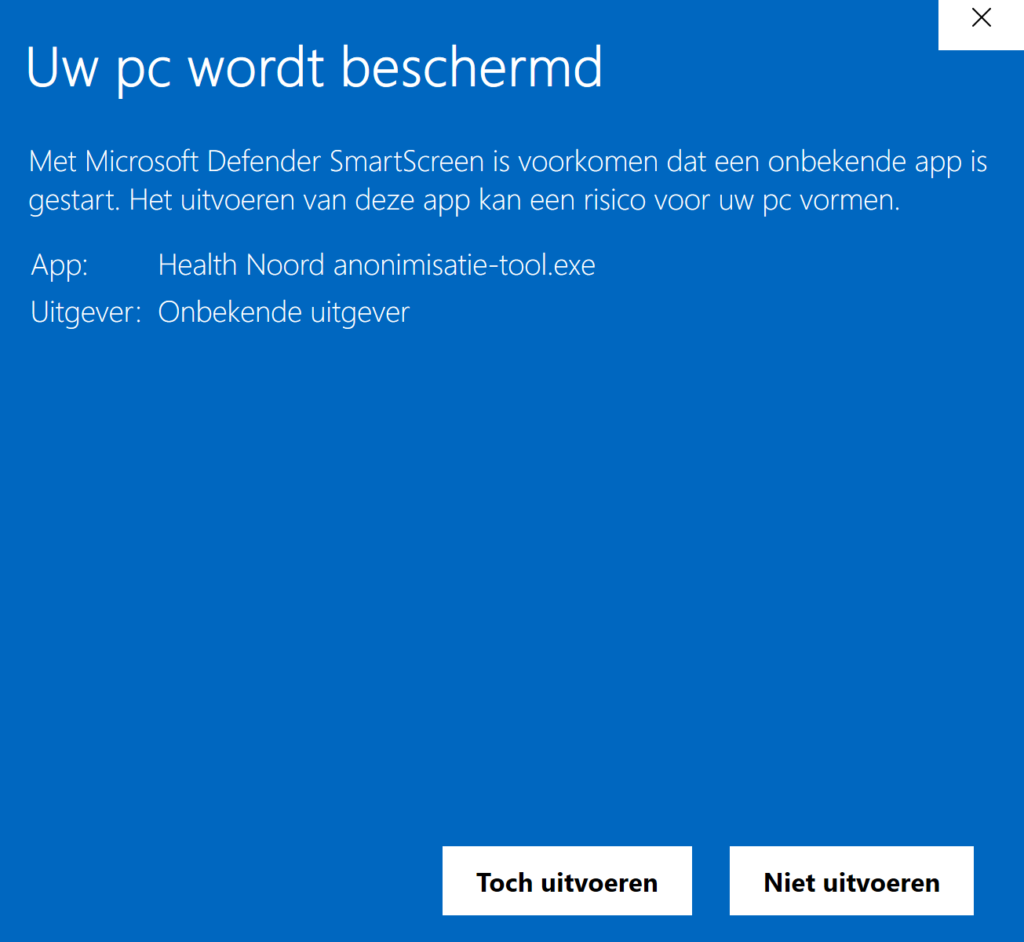
1. De gegenereerde tool (Health Noord Anonimisatie-tool.exe) is nog niet gecertificeerd, je kunt een beveiligingswaarschuwing krijgen dat het mogelijk onveilige software betreft. Deze kun je overrulen door op ‘Meer informatie’ te klikken en vervolgens ‘Toch uitvoeren’ te klikken.
2. De eerste keer opstarten van de tool vraagt, afhankelijk van de capaciteit van je computer, 1 tot 2 minuten. De tool moet initiele bestanden downloaden en initieren. De volgende keren van opstarten gaat binnen enkele seconden.
1.1 Benodigdheden
Een invoerbestand (.txt) met vrije tekst die je wilt anonimiseren
Een uitvoermap voor geanonimiseerde resultaten
Een map voor logbestanden
Optioneel zijn de aanvullende lijsten met namen en locaties die niet in de standaard anonimisaties opgenomen zijn:
patiëntenlijst (.txt)
medewerkerslijst (.txt)
locatielijst (.txt)
2. Overzicht van de interface
Hieronder zie je een screenshot van de hoofdinterface van de tool:
De interface bestaat uit drie hoofdonderdelen:
Bestanden selecteren (links)
Filterinstellingen (rechts)
Procesuitvoer (onderaan)
3. Bestanden selecteren
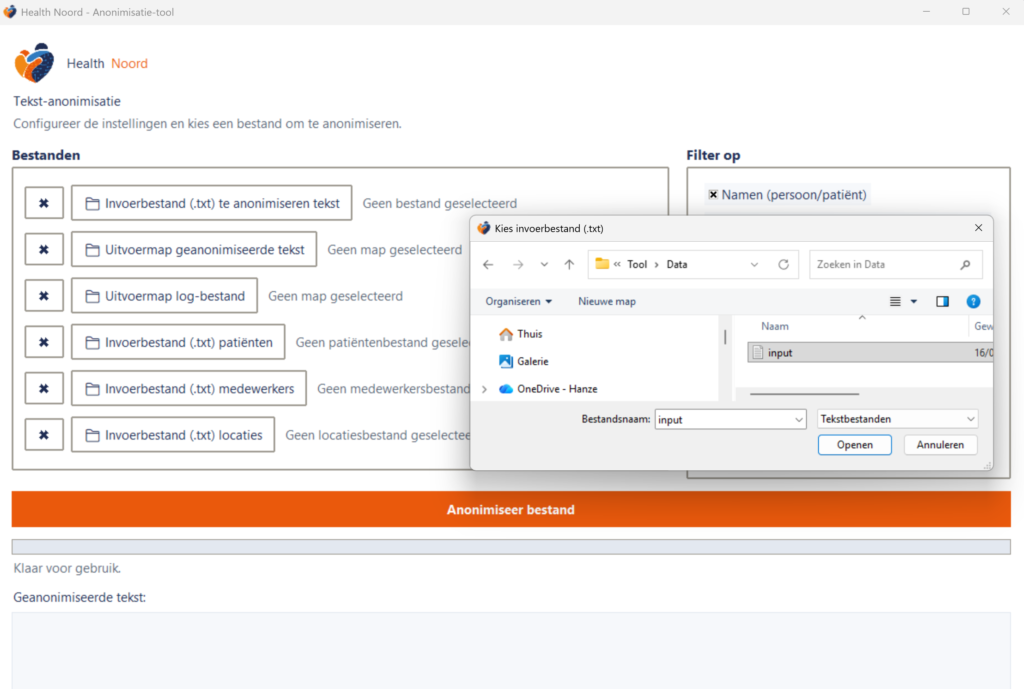
In het linkerdeel kun je alle benodigde invoer- en uitvoerbestanden kiezen.
3.1 Invoerbestand te anonimiseren tekst
Klik op Invoerbestand (txt) te anonimiseren tekst om het ruwe tekstbestand te selecteren.
3.2 Uitvoermap geanonimiseerde tekst
Kies een map waar de geanonimiseerde output wordt opgeslagen.
3.3 Uitvoermap log‑bestand
Selecteer een map voor logbestanden. Deze bevatten een overzicht van alle gedetecteerde entiteiten.
3.4 Optionele aanvullende lijsten
Gebruik deze voor extra nauwkeurige detectie:
Patiëntenlijst
Medewerkerslijst
Locatielijst
Alle bestandsopties zijn zichtbaar in het screenshot hierboven (linkerkolom).
4. Filterinstellingen
Aan de rechterkant van het scherm bepaal je welke persoonsgegevens moeten worden gefilterd. Je kunt de volgende categorieën aan- of uitzetten:
✔ Namen (persoon/patiënt)
✔ Locaties (plaats, straat, postcode, huisnummer)
✔ Instellingen (zorginstellingen, ziekenhuizen)
✔ Datums
✔ Leeftijden
✔ Identificatie (BSN, patiëntnummer)
✔ Telefoonnummers
✔ E-mailadres
✔ URL’s / websites
Deze instellingen zie je in het screenshot aan de rechterzijde.
5. Anonimisatie uitvoeren
Wanneer alle instellingen correct zijn:
Controleer of alle bestanden zijn geselecteerd.
Controleer of de gewenste filters zijn aangevinkt.
Klik op de oranje knop “Anonimiseer bestand”.
De tool start direct met het anonimiseren. De voortgang en status verschijnen in het venster onderaan de interface.
6. Resultaten bekijken
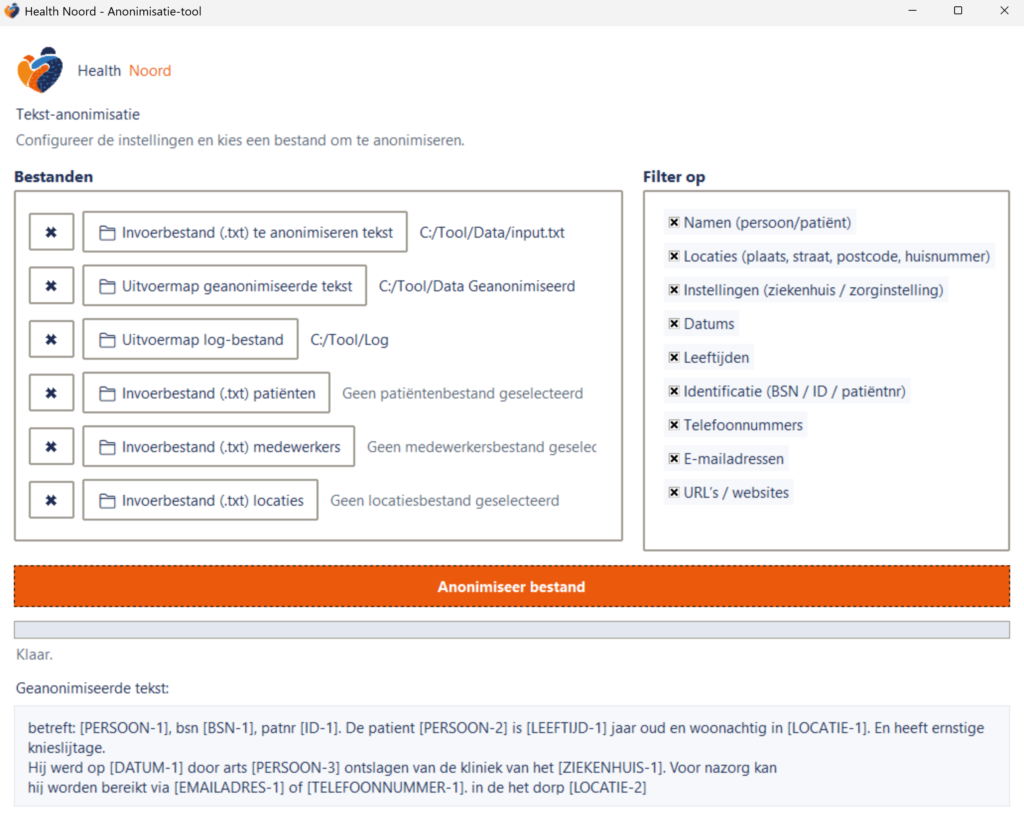
Na voltooiing wordt onderaan het scherm “Klaar.” weergegeven.
6.1 Geanonimiseerde tekst
De geanonimiseerde versie van de tekst wordt opgeslagen in de uitvoermap die je hebt opgegeven.
6.2 Voorbeeldweergave
Direct onder het scherm toont de tool een voorbeeld van de geanonimiseerde tekst, zoals in het screenshot te zien is.
Identificerende gegevens worden automatisch vervangen door labels zoals:
[PERSOON-1]
[DATUM-1]
[ZIEKENHUIS-1]
6.3 Logbestanden
De logbestanden helpen je controleren:
Welke gegevens zijn gedetecteerd
Waar in de tekst dit gebeurde
Of er ambiguïteiten waren
Deze staan in de uitvoermap voor logbestanden.
7. Tips voor optimaal gebruik
Voeg indien mogelijk naam- en locatielijsten toe voor betere herkenning, met name minder frequent voorkomende namen zullen niet herkend worden.
Een optie is eerst een anonimisering uit te voeren en de namen die niet geanonimiseerd zijn toe te voegen aan een naam-lijst die ook aan de tool wordt aangeboden.
Controleer handmatig de geanonimiseerde output.
Gebruik duidelijke bestandsnamen en mappenstructuren.
Bewaar logbestanden voor verantwoording richting interne privacy officers of onderzoekers.
8. Veelvoorkomende problemen
❗ Sommige namen worden niet gedetecteerd
→ Voeg een patiënten- of medewerkerslijst toe.
❗ Uitvoerbestand blijft leeg
→ Controleer of de uitvoermap correct is ingesteld.
❗ Locaties of datums worden niet verwijderd
→ Kijk of de filteropties zijn aangevinkt.
9. Ondersteuning
Voor vragen of feedback (Health Noord):
Dr. Talko B. Dijkhuis — t.b.dijkhuis@pl.hanze.nl